Lock-free Multithreaded "Find Duplicates" support in digiKam 7.3.0
Preface: Juggling between multiple image hosting web services
Like many other young kids in Brazil in the early 2000s, Fotolog (discontinued) was my first photo collection web service. From there, I switched to Flickr, back then a broad image service in which you could store high-resolution photos.
In the meanwhile, Orkut (re-activated?) was the most popular social network in Brazil, and I used to store some of my photos in there too. Orkut eventually got replaced with Facebook, which at the time made it simple to store e.g. a batch of photos from my trips around the world.
Then, came Google Drive, Google+ (discontinued), and later on Google Photos. Until 2019, Google Drive and Google Photos were in sync, but that service got discontinued too.
Finally, my personal NAS also acted as a photo storage device until recently, when Seagate discontinued its PersonalCloud web service and its NAS OS 4 operating system.
As you can imagine, my photo collections got scattered over multiple providers and naturally, an increasing amount of duplicated images with varying qualities and sizes evolved over the years.
To solve this, I decided to put all of these in a single database, and started searching for software to handle the duplicates. As a big fan of the KDE community, I chose digiKam, an open-source professional photo management software.
Part 1: How digiKam finds similar images
In order to find similarities between images, digiKam uses the Haar cascades classifier algorithm from OpenCV. An excerpt from its Fuzzy View documentation provides more details:
digiKam characterizes every image by a lengthy number using a special technique (Haar algorithm) that makes it possible to compare images by comparing this calculated signature. The less numerical difference there is between any two image signatures, the more they resemble each other.
Before you can have digiKam finding duplicates their signatures (or fingerprints) have to be calculated. This process is atomic in a sense that each signature can be calculated independently. The image signature is created when the image is imported in the database.
Once the list of images to compare is calculated, their fingerprints are obtained from the database and stored in a memory cache on-demand for faster look-ups.
Once the fingerprints are known, the images are then ready to be compared against each other. This process translates in the pseudo-code below:
for imageId in imagesToCompare {
similarImages = []
if (imageId not in signatureCache) {
signatureCache[imageId] = querySignatureFromDatabase(imageId)
}
for otherId in imagesToCompare {
if (imageId == otherId) {
continue
}
if (otherId not in signatureCache) {
signatureCache[otherId] = querySignatureFromDatabase(otherId)
}
diff = calculateDiff(signatureCache[imageId], signatureCache[otherId])
if (diff > threshold) {
similarImages << otherId
}
}
similarImagesDatabase[imageId] = similarImages
}
Part 2: Optimizing the sequential logic
This operation is implemented using a naïve O(n²) solution, and until recently was implemented sequentially on a single worker thread (search job). On a significantly large collection of photos, finding similar images could be an hours-long process that sub-utilized the computer’s capabilities.
Because each image gets its own similar images list, I realized this process could be broken down using in lock-free parallel threads. For that, I implemented the following:
- Resolve all image ids before starting the searches jobs.
- Create a shared Haar interface with signature cache to be used by all searches jobs in parallel.
- Spawn a given amount of worker threads (searches jobs) depending on the amount of CPU cores.
- Break down the whole “images to scan” set into iterator ranges, and assign each range to a dedicated worker thread.
- Rebuild (or update) the search albums in the database.
The step 3) can be run lock-free with some adjustments e.g. because we’re using constant iterator ranges, it is not possible to remove unused images from the cache when running multi-thread. Also, because we use ranges in step 3), sometimes the same search album is generated multiple times in separate threads using different reference images.
In step 4) we ensure the aggregated results are filtered so there’s only one search album with similar images per duplicates found.
This work has since been released in the digiKam 7.3.0 release.
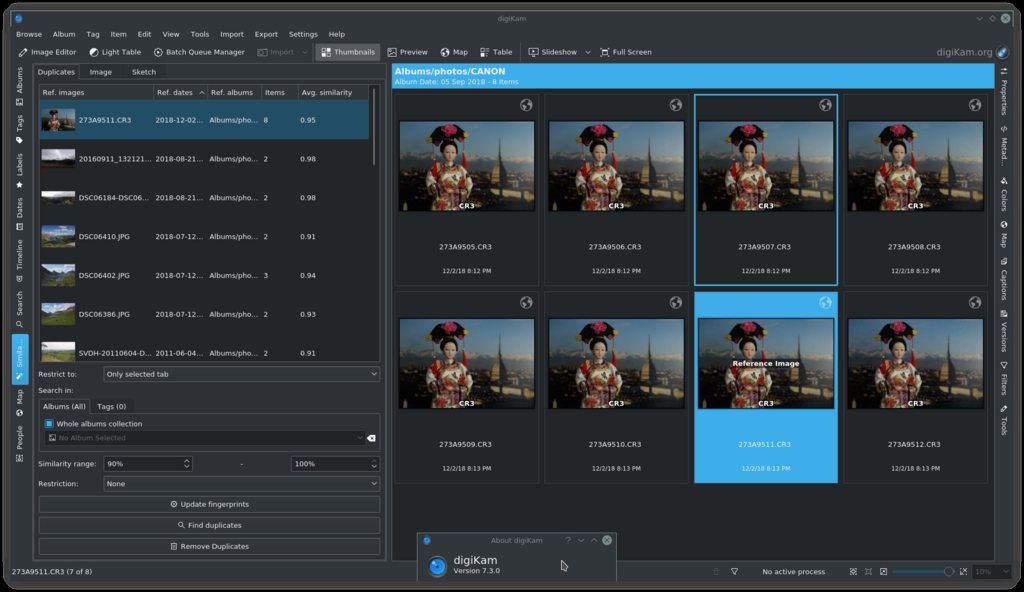 Find Duplicates tool in digiKam
Find Duplicates tool in digiKam
Special thanks to Gilles Caulier and Maik Qualmann for their code reviews ![]()